About two months ago, @maxdeviant and I began the project of making Zed extensible. In a code editor, extensibility can include many features that require many different capabilities, but for the first phase of the project, we have focused on extensible language support. We want people to be able to code in Zed in any programming language, not just a select few. We've just reached that first milestone, so it seems like a good time to share what we've done.
Language Support in Zed
Zed has two categories of language-specific features that we made extensible:
-
In-process syntax-based analysis of individual source files based on Tree-sitter. This requires a Tree-sitter grammar for each supported language, along with a set of Tree-sitter queries that describe how to use that grammar's syntax tree for tasks like syntax highlighting, auto-indent, etc. See my previous blog post for more information on how Zed uses Tree-sitter queries.
-
External servers that provide semantic understanding via the Language Server Protocol. This requires specifying how to run a given language server, how to install and upgrade that server, and how to adapt its output (completions and symbols) to match Zed's style.
In this first post, I'm going to focus on the Tree-sitter part. We'll describe how we handled extensible language servers in a follow-up blog post.
Challenges with Packaging Parsers
The hard part about letting extensions add Tree-sitter parsers to Zed is that Tree-sitter parsers are expressed as C code. Grammars are written in JavaScript, and converted into C code by the Tree-sitter CLI. Tree-sitter is designed this way for a variety of reasons. In short, some kind of turing-complete language is needed, and C code has the useful property that it can be consumed from almost any high-level language via C bindings. But sadly, C code is not the most convenient artifact to distribute to end users.
One possible method of distributing extensions would have been to ship the C code itself, compile it on the user's machine with their C compiler when they install an extension, and then dynamically load the resulting shared library. This is essentially what we did for Atom (using the Node.js packaging facilities). Other editors that use Tree-sitter, like Neovim and Helix, also use this same approach.
But for Zed, we wanted a smooth, safe plugin-installation experience that didn't depend on the user's C compiler. We wanted to make it impossible for an extension to crash Zed. Tree-sitter parsers consist mostly of auto-generated C code that is fairly safe, but grammar authors can also write external scanners that contain arbitrary logic, and we had seen crashes due to bugs in third-party external scanners. We would never be able to prevent these kinds of crashes if we loaded extensions directly as shared libraries.
Obviously, We Used WebAssembly. But How?
You probably won't be surprised to find out that the solution involved WebAssembly. I had already built a WebAssembly binding for Tree-sitter, which lets you run Tree-sitter parsers on the web, via a JavaScript API. WebAssembly (or wasm for short) is a great format for distributing parsers, because it's cross-platform, and it's designed for running untrusted code safely.
It was not obvious though, how to use wasm builds of parsers in our native code editor.
When you run a wasm program, your application provides the program with an array of bytes that will serve as its linear memory. The wasm code can then only read or write to those bytes. But in Zed, when running a parser, a lot of data needs to be exchanged. On each keystroke, Zed needs to pass in source code, and the parser needs to return a concrete syntax tree - a data structure that's much larger than the corresponding text. When parsing incrementally, each syntax tree shares common structure with the previous syntax tree, and Zed frequently sends these syntax trees to background threads, where they are used for various async tasks.
So if we ran parsers entirely via wasm, we would need to copy a huge amount of data out of the wasm memory on every parse. So simply compiling Tree-sitter and the grammars to wasm would not suffice.
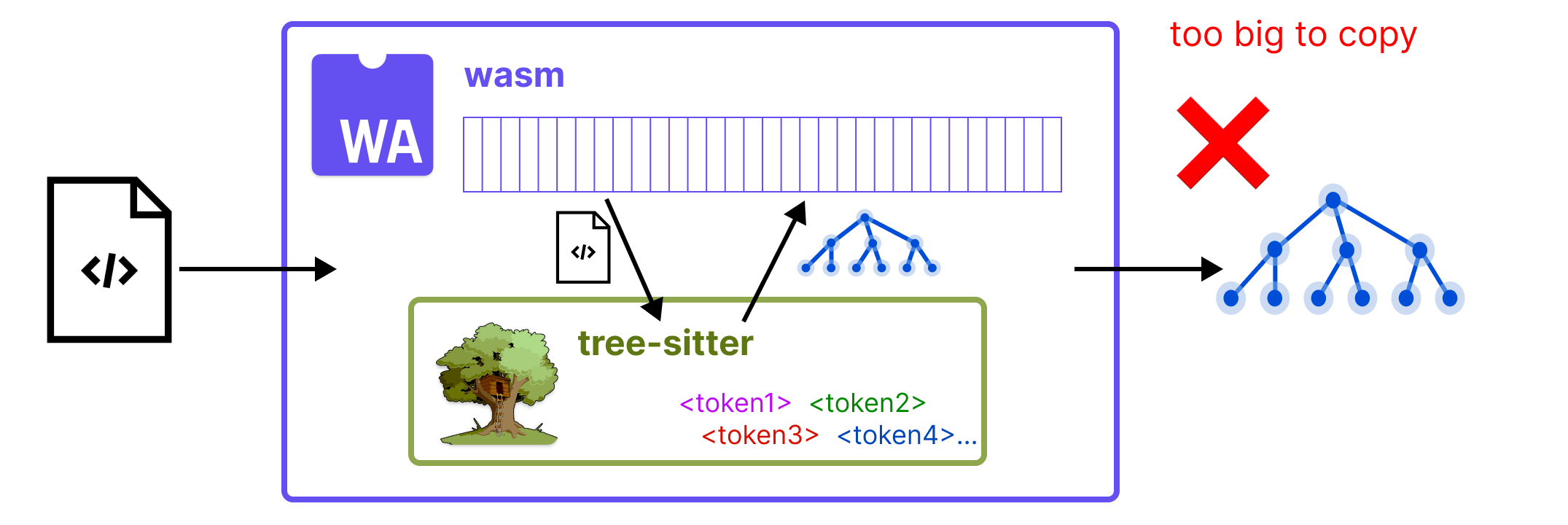
A Hybrid Native + WebAssembly System
We decided to take advantage of the fact that Tree-sitter parsers are table-driven. Most of the generated C code consists of static arrays that represent a state machine.
Like other table-driven parsing frameworks, Tree-sitter's parsing is divided into two parts. The lexing phase processes text character-by-character, producing tokens. Each grammar's lexer is implemented as some auto-generated C functions, and some optional hand-written ones. The parsing phase is more complex, and is where syntax trees are actually constructed. Crucially, parsing is driven entirely by static data.

This division between the two phases enables a unique architecture in which we load a parser from a wasm file, but most of the static data in that wasm file is copied out of the wasm linear memory into a native data structure. During parsing, we use a WebAssembly engine whenever we need to run a lexing functions, but all of the rest of the computation is done natively, in exactly the same way as when using a natively-compiled Tree-sitter parser.
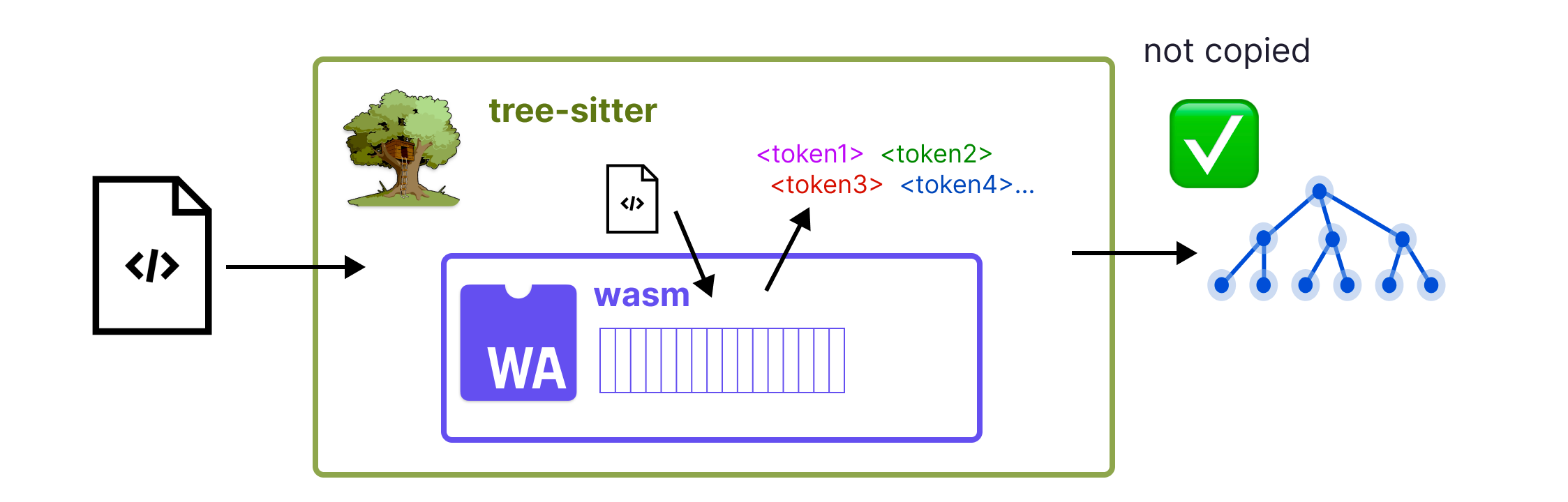
Lexing is the least expensive part of the parsing process, and is also the only part where custom hand-written code is involved. So in many ways, this hybrid native + wasm design gives us the ideal combination of safety and performance.
Extending the Tree-sitter API
To enable this new approach to parsing, we added some new primitives to the Tree-sitter library.
For background, the Tree-sitter core library provides a Parser type, which is used to parse source code, creating Tree objects. To use a parser, you must assign it a Language, which is an opaque object generated from a particular grammar, and provided in a separate library for that grammar.
let mut parser = tree_sitter::Parser::new();
let python_language = tree_sitter_python::language().unwrap();
parser.set_language(&python_language).unwrap();
let tree = parser.parse("def secret():\n return 42\n", None).unwrap();We added a new type called WasmStore, which integrates with the Wasmtime wasm engine and lets you create Language instances from WASM binaries. These language objects work exactly like the normal, native language objects, except that when using them, your parser needs to have a WasmStore assigned to it. This is needed because the wasm store allows parsers to call wasm functions during lexing.
let engine = wasmtime::Engine::default();
let mut wasm_store = tree_sitter::WasmStore::new(&engine);
const WASM_BYTES: &[u8] = include_bytes!("tree-sitter-python.wasm");
let python_language = wasm_store.load_language("python", WASM_BYTES).unwrap();
parser.set_wasm_store(wasm_store);
parser.set_language(&python_language).unwrap();Except for that one difference, the languages loaded from WASM behave exactly like the natively-compiled ones. The resulting syntax trees are the same, and aren't coupled to a wasm store.
Implementation Highlights
Like the rest of the Tree-sitter library, these new APIs are implemented in C. They use Wasmtime's excellent C API. You can find their full implementation here.
When using wasm, you have very low-level control over the details of how modules are linked and loaded. Modules declare imports for several constants that control how the wasm linear memory is laid out - the address where their static data should be placed, the base address of the call stack, and the start address of the heap. Here is a diagram of how a tree-sitter WasmStore's wasm memory is laid out:

Modules also declare imports for all of the functions that they depend on. As mentioned above, Tree-sitter grammars can include hand-written source files called external scanners. These files often use functions from the C standard library - character-categorization functions like iswalpha/iswspace, string-handling functions like strlen/strncmp, and memory-management functions like malloc/free for carrying small amounts of state. To handle imports like these, the Tree-sitter library embeds a small wasm blob containing a subset of functions from libc that are available for external scanners.
One cool thing about providing our own mini-libc is that we don't need to use the standard versions of the memory-allocation functions malloc, free, etc. We know that the memory allocated by external scanners is only needed for the duration of a single parse, so we implemented our own tiny malloc library that uses a bump-allocation. This allocator has much less overhead than a general-purpose malloc implementation, and requires much less wasm code. Best of all, it makes it impossible for external scanners to cause memory leaks! We can simply reset the entire wasm heap at the beginning of each parse.
Using Language Extensions
As soon as we shipped this feature, the Zed community began shipping language extensions. The current number of language extensions available in Zed's extension store is at 6️⃣7️⃣ and counting. These languages support all of Zed's syntax-aware features: syntax-aware selection, the outline view, syntax-based auto-indent, and of course syntax highlighting.
To browse the extensions, click Zed > Extensions in the application menu. If there's a language that you use that isn't yet supported, we invite you to open a PR on our extensions repository. Or just open an issue and ask for help. See the "Developing Extensions" docs to get started.
Closing
Using wasm to package Tree-sitter grammars has worked wonderfully for Zed, and the Wasmtime engine has been fantastic to use. Tree-sitter grammars are just one piece of Zed's extension system. In a later post, we'll talk about all of the other ways we're using wasm to make Zed extensible. Thanks for reading!