When you're deep in a flow state while programming, you think about your program in terms of its logical structure, not its text representation. A good code editor should help you to stay in that headspace, letting you clearly see the code's structure and manipulate it, without worrying about individual characters.
Like many other editors, Zed uses the Language Server Protocol for several standard kinds of language intelligence. But there are many other features that require the editor itself to understand the code on a syntactic level. In this post, I'll explain how Zed approaches syntax-aware editing, and show how some of Zed's syntax-related features are implemented.
Tree-sitter
Parsing code in an editor poses some challenges that most parsers aren't designed to address. The source code changes frequently and needs to be re-parsed quickly. Often, the code is temporarily invalid in the area where you're editing, and you still need to parse the rest of the file correctly. There are many different languages to parse, and all of the editor's features need to work consistently across all of those languages.
That's why I spent several years writing Tree-sitter, an open-source parsing framework that works within these constraints. Tree-sitter parses code using the precise formalism of context-free grammars, with an algorithm called Generalized LR parsing (or GLR), which makes it possible to write a grammar for just about any programming language. It uses incremental parsing to allow efficient re-parsing after edits, and features a novel error-recovery technique that lets the parser produce useful results even when the file is in invalid state.
Using Concrete Syntax Trees
When you parse a file with Tree-sitter, it produces a data structure called a concrete syntax tree (or CST), which is like an abstract syntax tree, except that it retains information about the location of every token in the document. This is important for applications where you're viewing and manipulating the code itself, not just extracting its meaning. But once we have a concrete syntax tree representing the structure of a source file, how can we use that CST to improve the code-editing experience?
One simple application of the CST is a feature called syntax-aware selection, which consists of two commands in the editor: "select larger syntax node", and "select smaller syntax node", bound to the keys alt-up and alt-down by default. These commands let you quickly select the code that you want to change without having to move the cursor character by character.
These commands are especially useful when you're trying to edit multiple snippets of code at once with multiple cursors. Often, the snippets you want to edit are different in length, but the same syntactically.

For implementing these commands, we don't need any information other than the concrete syntax tree itself, because we don't care about specific types of syntax nodes, all we need to know is which ranges in the document correspond to nodes in the syntax tree. For most other syntax-aware features though, we need more details about the nodes. Let's discuss how those features work.
Tree Queries
There are many code-analysis tasks where we need to search a syntax tree for a specific set of structural patterns. To make this type of task easier, Tree-sitter includes a query engine. Tree queries let you write syntactic patterns in a simple, declarative language, and efficiently iterate over all of the groups of nodes in a syntax tree that match those patterns.
Here's an example query for a JavaScript syntax tree. In this query, we're looking for three different patterns. The first pattern matches any assignment of an arrow function to an object property (like a.b = (c) => d). The second pattern matches any reference to a property of this (like this.x). And the final pattern matches any identifier.
(assignment_expression
left: (member_expression
property: (property_identifier) @the_assigned_method)
right: (arrow_function))
(member_expression
object: (this)
property: (property_identifier) @the_property_of_this)
(identifier) @the_variableIn the query, the names starting with an @ sign, like @the_assigned_method and @the_property_of_this, are arbitrary. They are called captures, and you use them to assign a given name to the preceding node in a pattern. Every time that pattern matches, you can then retrieve the corresponding matched nodes using those capture names.
When you construct a query, Tree-sitter compiles the query's source code into a compact state machine. The state machine is structured to enable finding all of the query's matches in a single depth-first walk of a syntax tree. During execution of the query, we walk the syntax tree and maintain a set of in-progress matches. When stepping into each node in the tree, we advance any matches whose next step is satisfied by that node, remove any matches that have failed, and report any completed matches to the calling application.
The query language has other features for expressing more complex patterns. For more information, see the query section of the Tree-sitter documentation.
Zed uses tree queries to express all language-specific rules for processing syntax trees. This makes integrating a new language relatively simple: there's no need to write custom procedural code for each language: we just add a Tree-sitter parser and a set of queries.
Syntax Highlighting
Good syntax highlighting uses colors consistently to indicate the role of each token in a file. Historically, most code editors have performed syntax highlighting using regular expressions, which operate on one line of text at a time, and recognize certain distinctive code constructs in an approximate way. This approach generally produces highlighting that's frustratingly inconsistent.
Using a syntax tree, we can highlight code much more precisely and consistently. For each language, we just need to specify how the various styles and colors in a theme should map to different nodes in the syntax tree.
Zed uses a tree query to specify this mapping. The highlighting query uses capture names that match the names of styles in a theme. For example, here's an example highlighting query for JavaScript:
["do" "for" "while"] @keyword
(function
name: (identifier) @function)
(pair
key: (property_identifier) @function.method
value: [(function) (arrow_function)])In this query, the keywords do, for, and while would appear in the theme's keyword color, names of function declarations would appear in the function color. And object literal keys whose values are functions would appear in the function.method color (or just the function color, if the theme didn't specify a specific color for function.method).
With this approach, Zed themes can be very simple, and decoupled from any particular language. Here's a snippet from Zed's "One Dark" theme:
{
"keyword": {
"color": "#B478CF"
},
"function": {
"color": "#74ADE9"
},
"emphasis.strong": {
"color": "#C0966B",
"weight": "bold"
},
"link_text": {
"color": "#74ADE9",
"italic": false
}
}Symbol Outlines
A symbol outline makes code easier to navigate by listing the symbols defined in a file, and showing their hierarchical relationship. In Zed, we present a file's outline in two ways. The breadcrumbs are always visible at the top of the editor and list the symbols that contain the cursor position. And the outline modal lists all of the file's symbols, and lets you fuzzy-filter them and jump to any symbol in the file.
The outline modal is very powerful, because the fuzzy search operates on more than just one symbol name. For example, you can type a query like buf lang to quickly bring up all of the symbols that match lang and are within a parent symbol that matches buf. This would include methods like Buffer::set_language, and BufferSnapshot::language_at
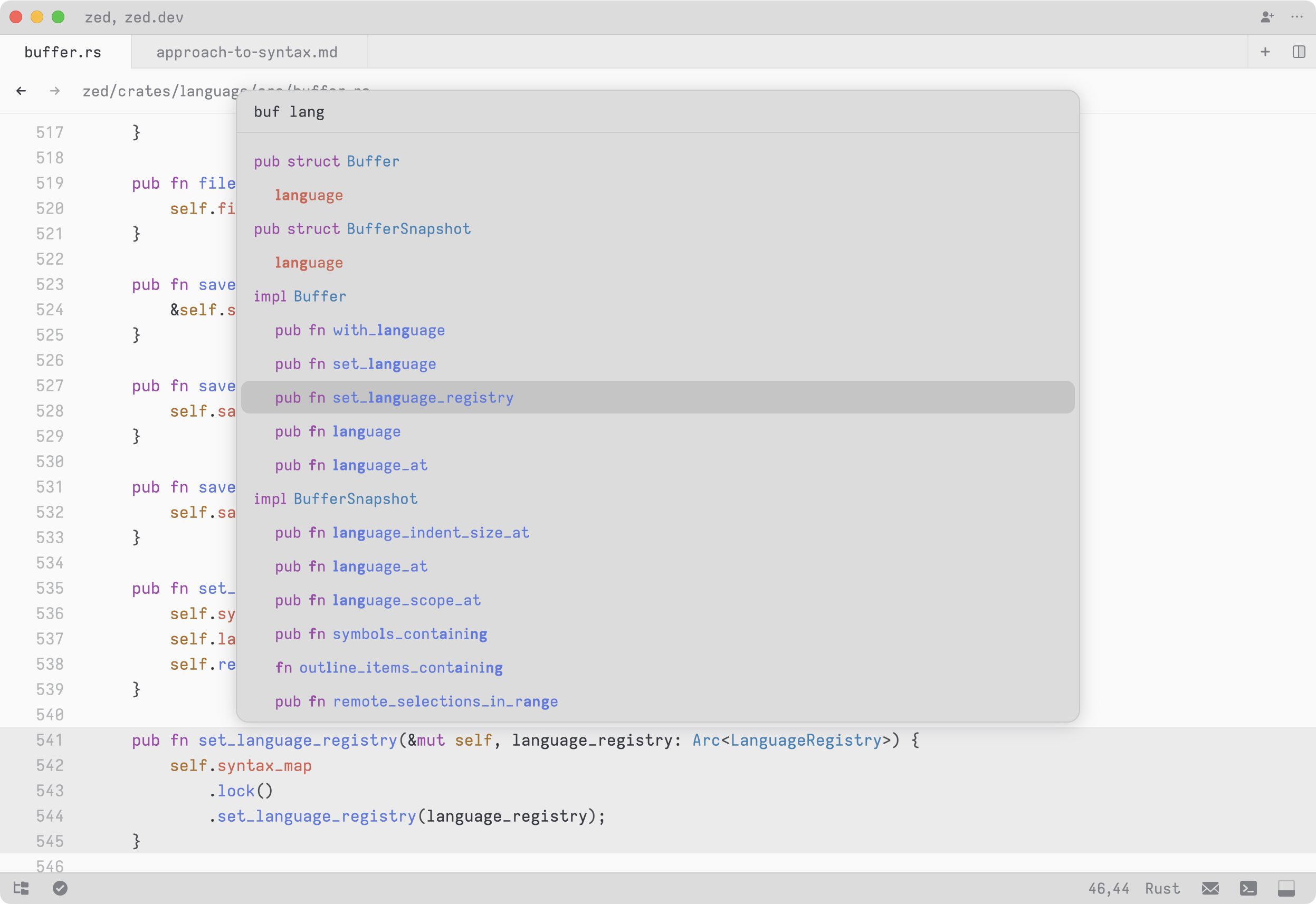
The items in the outline contain some context besides just the symbol names, such as function names like fn in Rust. If your fuzzy query contains multiple words, you can match on these words in the context, in addition to the name itself. For instance, you can list all of the public async functions in a file by typing pub async fn.
In order to make the outline work this way and feel uniform across all of the languages that we support, we decided not to use the Language Server Protocol's version of this feature. A symbol outline is syntactic in nature, and local to one file, so we can implement it using another Tree-sitter query. This gives us complete control over the presentation of the outline.
Here's a snippet from the the outline query for Rust:
(impl_item
"impl" @context
trait: (_)? @name
"for"? @context
type: (_) @name) @item
(function_item
(visibility_modifier)? @context
(function_modifiers)? @context
"fn" @context
name: (_) @name) @itemIn this query, the @name capture marks the syntax node containing the symbol's name. The @item capture marks the node for the symbol's entire definition, which is important for determining the nesting relationship between different symbols. And the @context capture any nodes whose text should be included in the outline, to help show what kind of definition the symbols is.
Auto-Indentation
An editor's language-awareness comes into play when writing code as well as when reading it, in the form of automatic indentation. Most languages have clear indentation conventions that can be expressed in terms of specific syntactic constructs in where the indentation should be increased.
Zed expresses these conventions using a third query. In the indent query, every match is used to compute an indentation range - a range of the file in which every line should be indented one level further than the line where the range starts. The @indent capture marks a node whose extent defines an indentation range. The optional @start and @end captures can be used to shrink the indentation range.
For example, in this indent query for JavaScript, the contents of statement blocks are indented up until the line with the closing curly brace. And several types of multi-line expressions and statements are indented relative to the line where they begin:
(statement_block "}" @end) @indent
[
(assignment_expression)
(member_expression)
(if_statement)
] @indentThis simple query allows Zed to correctly auto-indent code for which most code editors completely give up on indentation adjustments:
if (one)
// this line is indented because it's part of the if statement
two = three.four // this line is indented because it's part of a member expression
.five(() => {
six({
seven: eight,
})
})
// this line is dedented to match the previous statement.
nine()Multi-language Documents
For many languages, one syntax tree is not enough to model a source files's entire structure. For example, in an HTML file, each script tag contains a separate JavaScript document. And in a templating language like ERB, the file consists of one HTML document and one Ruby document, where each one is broken into many disjoint ranges that are interspersed. Even in Rust, the argument passed to each macro invocation must be re-parsed as a mini Rust document, in order to understand the structure of the Rust expressions and declarations inside.
We refer to these inner syntax trees as language injections (a term coined by the TextMate editor). As with all of the previous features, Zed uses a query to express each languages's rules for language injection. For example, this pattern from the HTML injection query indicates that the inside of a script tag should be parsed as JavaScript:
(script_element
(raw_text) @content
(#set! "language" "javascript"))Managing the Set of Syntax Trees
In some languages, there can be a very large number of injected syntax trees for a given buffer. For example, in Rust, files often contain many macro invocations, and we compute a separate Rust syntax tree for each those invocations.
When reading from the set of syntax trees, we need a way to efficiently retrieve the ones that intersect a given range of the file. To make this possible, we store the set of syntax trees in a copy-on-write B-tree data structure called a sum tree, which we use pervasively in Zed for storing sequential collections (and which we'll discuss further in an upcoming blog post).
When the buffer is edited, we need update the set of syntax trees to reflect the edit. Any trees that intersect the edit need to be re-parsed. Then, within each of those trees, we need to find any injections that were added or removed. To do this, we run the injection query over the ranges of the tree affected by the edit. The new injected syntax trees might themselves contain injections, so this is an iterative process!
Although it's complex, this process is very fast, thanks to Tree-sitter's incremental parsing and queries, and to the sum tree's efficient seeking and slicing operations. And even in unusually slow cases, the editor stays responsive, because sum trees use an efficient copy-on-write structure that allows us to perform this update on a background thread even while a previous snapshot of the data is being actively used on the main thread!
Wrapping Up
Years ago, when I began work on Tree-sitter, I dreamed of one day using a lightweight code editor that understood code's syntax on a deep level. Now that we've built a solid foundation of syntax-awareness into Zed, for the first time, I have a tool that works the way that I want. There is a lot of room to explore how we can further improve the code-editing experience using these capabilities. Thanks for reading!