What do you say when someone asks you: "where's your cursor?" Probably something like "line 18", or if you're feeling good that day and it's a single digit you might add the column too: "line 18, column 5." Lines and columns — simple, easy.
Text editors, Zed included, also use lines and columns to describe positions, but — to my surprise when I first explored Zed's codebase — there's quite a few other coordinate systems in Zed. There are offsets, offsets in UTF-16, display points, and anchors.
To finally understand these different text coordinate systems and when which one is is used, I talked to Nathan and Antonio, two of Zed's co-founders, and asked them to walk me through it all, from Point to DisplayPoint to Anchor.
Companion Video
Text Coordinate Systems
This post comes with a 1hr companion video, in which Thorsten, Nathan, and Antonio start by writing some tests around Points and Offsets and then venture into DisplayPoint and Anchor land.

Point
First, let's talk about the most obvious form of text coordinates in zed: the Point. A Point is a "zero-indexed point in a text buffer consisting of a row and column". It looks like this:
// crates/rope/src/point.rs
struct Point {
row: u32,
column: u32,
}No surprise there. Row and column, meat and potatoes. Here's a snippet from one of our tests to illustrate how Points are used:
let last_selection_start = editor.selections.last::<Point>(cx).range().start;
assert_eq!(last_selection_start, Point::new(2, 0));The assertion here tries to ensure that the selection starts on line 3 (zero-indexed!) at column 0.
A handy property of Points is that they make it easy to express navigation along lines. Moving a cursor down by one line is as simple as incrementing the row value:
let old_point = Point::new(18, 5);
let new_point = Point::new(point.row + 1, point.column);From line 18 to line 19 with a simple +1. Sweet. If you want to go back, make that a -1. But what if you want to navigate left or right?
That's can get tricky since different lines might have different lengths. Simply adding or subtracting columns might give you an invalid position in the document. Turns out that the seeming simplicity of Points is a little bit deceptive — Points require careful handling.
In Zed, for example, Points follow what Nathan calls "typewriter logic": a carriage return – adding a new line, essentially – resets the column count to zero, because on a typewriter the carriage would also start at the beginning of the next line.
To illustrate, here's a test that passes in Zed's codebase. Pay attention to the columns:
fn test_point_basics() {
let point_a = Point::new(5, 8);
let point_b = Point::new(2, 10);
let result = point_a + point_b;
assert_eq!(result, Point::new(7, 10));
}Note that the two lines — 5 and 2 — are added together, but the resulting column is 10, which is the column value of point_b.
Text math with points - not as straightforward as I thought.
Offset
Offsets are another type and text coordinate system in Zed. They are straightforward. An Offset is an absolute number that represents a position in a document as a single count of bytes from the start of the document.
The start of a document is Offset::new(0), the position of W in Hello World is Offset::new(6), and the last character in a document is Offset::new(document.len() - 1), assuming that each character is a single byte.
Offsets are particularly useful when dealing with operations that span multiple lines of text. Selections, for example:
let start = Offset::new(10);
let end = Offset::new(50);
let selection = Selection::new(start, end);No need to worry about columns at all — from this character to that character, including the newlines. That's easy to express with Offsets.
But, again, there's a tiny gotcha with Offsets too, because Offsets alone aren't enough.
UTF-16, what?
When exploring Zed's codebase I found it really interesting that you'll find far more OffsetUtf16s than Offsets. There are PointUtf16 too. I personally never had to deal with UTF-16, except when working with language servers and the language server protocol, which used UTF-16 encoding to calculate and describe text document positions and offsets.
Turns out that's exactly why Zed has OffsetUtf16 and PointUtf16 too: to communicate with language servers. Here, for example, is a method that looks up the definition for a given position in the buffer:
fn definition<T: ToPointUtf16>(
&self,
buffer: &Model<Buffer>,
position: T,
cx: &mut ModelContext<Self>,
) -> Task<Result<Vec<LocationLink>>> {
let position = position.to_point_utf16(buffer.read(cx));
self.definition_impl(buffer, position, cx)
}The position — a T that implements the ToPointUtf16 trait — is converted to a PointUtf16 before being sent to the language server. Under the hood, this might end up calling the following method on our Rope data structure:
// crates/rope/src/rope.rs
impl Rope {
fn point_to_point_utf16(&self, point: Point) -> PointUtf16 {
if point >= self.summary().lines {
return self.summary().lines_utf16();
}
let mut cursor = self.chunks.cursor::<(Point, PointUtf16)>();
cursor.seek(&point, Bias::Left, &());
let overshoot = point - cursor.start().0;
cursor.start().1
+ cursor.item().map_or(PointUtf16::zero(), |chunk| {
chunk.point_to_point_utf16(overshoot)
})
}
}In order to make sense of every line here, I recommend reading the Zed Decoded article on the Rope and SumTree data structures. For now it's enough to know that the point I want to make is this: UTF-16, due to language servers, is so important to Zed that the SumTree, with which the Rope is implemented, already indexes UTF-16 points and offsets, resulting in two new text coordinate systems - PointUtf16 and OffsetUtf16 — and making the conversion to and from UTF-16 very quick.
DisplayPoints
If we climb up the abstraction ladder and leave offsets, rows, and columns behind, we next end up at DisplayPoint. What's a DisplayPoint?
// crates/editor/src/display_map.rs
struct DisplayPoint(BlockPoint)A DisplayPoint is a new type around BlockPoint. What's a BlockPoint?
// crates/editor/src/display_map/block_map.rs
struct BlockPoint(pub Point);A BlockPoint is a... Point — wait, what? Does that mean we didn't climb the abstraction ladder at all but instead made a turn in the abstraction hamster wheel?
Not quite! A DisplayPoint is a Point, yes, but in this context — inside the DisplayPoint and inside the editor crate — the rows and columns of the Point have a different meaning. They don't refer to their counterparts in a text file on disk but to the rows and columns that you can see, the rows and columns that are displayed inside the editor. Hence DisplayPoint.
Take a look at this screenshot:
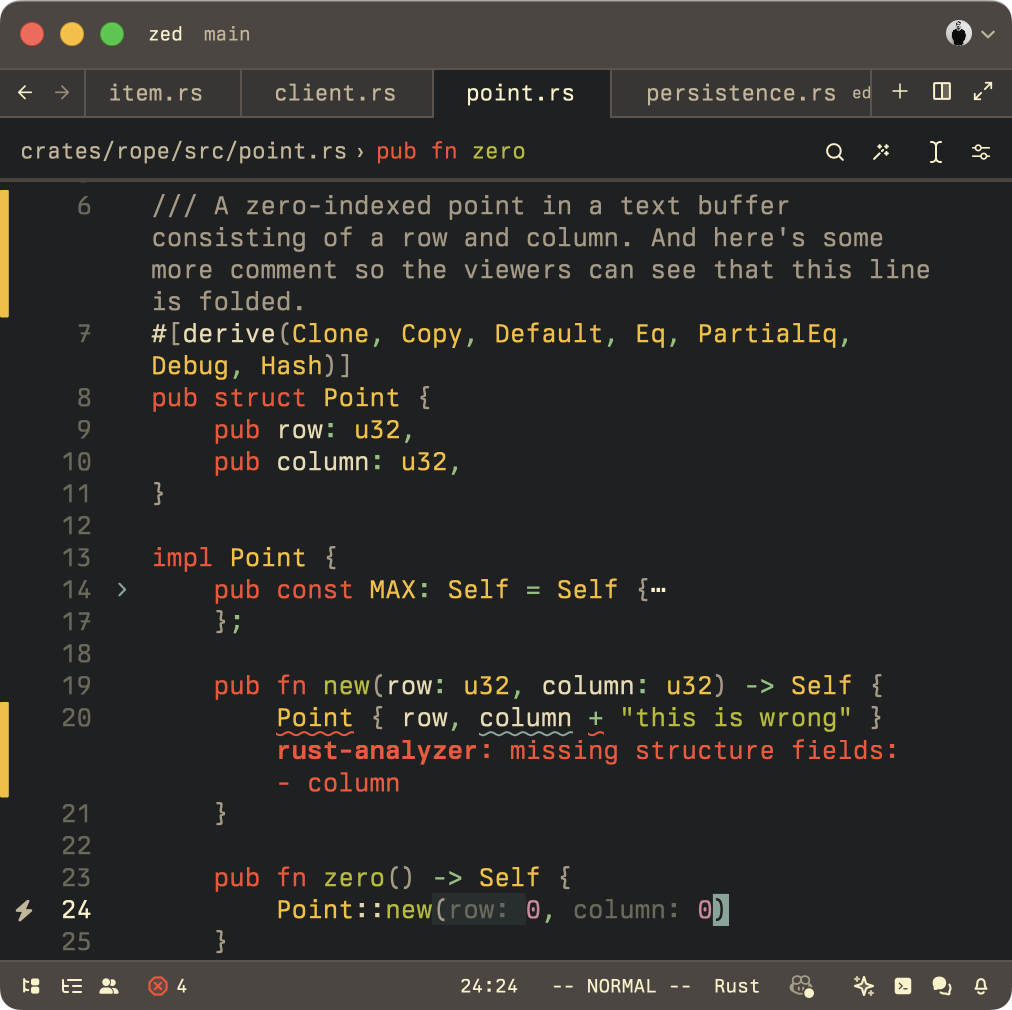
What's the position of the cursor? Look closely. As a plain-old Point (zero-indexed!) it would be line 23 and column 23. But as a DisplayPoints the cursor's position is line 29 and column 36!
That's because a DisplayPoint describes a position on the DisplayMap (something which we'll get to in a future episode of Zed Decoded, hopefully) and takes into account
- soft-wrapping
- folding
- inlay hints
- tabs
- blocks & creases
In that screenshot, you can see that line 6 is soft-wrapping and taking up more than a single line. The definition of Point::MAX is folded. A block is showing a diagnostic error. And in the zero() method, where the cursor resides, there are two inlay hints to the left of the cursor.
The DisplayPoint allows Zed to take all of that into account and accurately describe where the cursor is positioned — between wrapped lines, diagnostics, folds, inlay hints, and so on.
Here's a modified version of a test that I found to be very illustrative of what DisplayPoint does:
// Modified version of a test in crates/editor/src/display_map.rs
async fn test_zed_decoded(cx: &mut gpui::TestAppContext) {
// [... setup ...]
let font_size = px(12.0);
let wrap_width = Some(px(64.));
let text = "one two three four five\nsix seven eight";
let buffer = MultiBuffer::build_simple(text, cx);
let map = cx.new_model(|cx| {
DisplayMap::new(
buffer.clone(),
font("Helvetica"),
font_size,
wrap_width,
// [... other parameters ...]
)
});
let snapshot = map.update(cx, |map, cx| map.snapshot(cx));
// Given the above constraints — font_size, wrap_width, ... — the text above
// is displayed in 5 lines.
assert_eq!(
snapshot.text_chunks(DisplayRow(0)).collect::<String>(),
"one two \nthree four \nfive\nsix seven \neight"
);
// DisplayPoint(1, 0) is equivalent to Point(0, 8)
assert_eq!(
DisplayPoint::new(DisplayRow(1), 0).to_point(&snapshot),
Point::new(0, 8)
);
// DisplayPoint(1, 2) is equivalent to Point(0, 10)
assert_eq!(
DisplayPoint::new(DisplayRow(1), 2).to_point(&snapshot),
Point::new(0, 10)
);
// DisplayPoint(4, 1) is equivalent to Point(1, 11)
// (This is the "i" in "eight")
assert_eq!(
DisplayPoint::new(DisplayRow(4), 1).to_point(&snapshot),
Point::new(1, 11)
);
}Here's what this test says. Given the text...
one two three four five
six seven eight... and a font size of 12 pixels, wrap width of 64 pixels, the font Helvetica, and a bunch of other parameters, the text will be displayed like this:
one two
three four
five
six seven
eightAnd the DisplayMap (here as a snapshot in the local variable snapshot) allows us to translate between the "real" Points and the DisplayPoints:
Point::new(0, 10)is displayed atDisplayPoint::new(1, 2)Point::new(1, 11)is displayed atDisplayPoint::new(4, 1)
Pretty neat, right?
There's quite a few things going on under the hood here that I'd love to examine more, but we're already running long, so let's move on to the next coordinate system. Or at least what I thought would be a coordinate system, but as it turns out isn't: anchors.
Anchors
Before my conversation with Nathan and Antonio (you can watch the companion video here) I knew of anchors — I've seen the Anchor type and various related methods in the codebase — and assumed that they are yet another way to represent a position in a text document — another coordinate system.
That, as it turned out, was a slightly wrong assumption. Anchors are related to positions in text documents, but very different from Points, Offsets, or DisplayPoint.
Say you have a text document like this:
Hello World!An Anchor allows you to point to one side — left or right — of a given character in this document. You can, for example, create an anchor that points to the left side of the W here. That would be close to a Point::new(0, 6) except not quite: the Point describes the location of the W in this version of this document, the Anchor would stick to the side of the W, even when it's edited.
In Nathan's words:
An anchor is a logical coordinate. You can create an anchor on the right side of a character or the left side of a character. Then, at any point in the future, you can always redeem the anchor and get the position of the character that you essentially marked or anchored. Even if editing has occurred in the meantime, even if that code's been deleted, or that character's been deleted, you could still get the position of its tombstone — where it would be had it not been deleted, or where it would emerge if that delete is undone.
So if we were to attach an anchor to the left side of the W above and afterwards the text document would be edited to look like this:
Hello and good day to you, World!We could still take our anchor and "redeem" it, turning it into the actual Point at which the W now resides.
That makes total sense for a collaborative text editor: if your cursor sits on the W and someone comes along and edits the text to the left of it, you want your cursor to stay on the W and not the text-floor changing beneath your cursor-feet.
If you look at the definition of Anchor you can see how closely tied to Zed's collaborative nature and CRDTs it is:
// crates/text/src/anchor.rs, slightly simplified
/// A timestamped position in a buffer
struct Anchor {
timestamp: clock::Lamport,
/// The byte offset in the buffer
offset: usize,
/// Describes which character the anchor is biased towards
bias: Bias,
buffer_id: Option<BufferId>,
}The timestamp here is a Lamport timestamp, a logical timestamp. In our conversation, Antonio said that timestamp isn't a good name for the field here, it used to be called id and that's also a better way to think about it. Nathan explains:
In a CRDT, or at least our CRDT implementation, every piece of text, whether it's a character or a big block of pasted text or something else that's inserted, is viewed as an immutable block. That immutable block is given a unique ID, an ID that's unique across the cluster.
The timestamp: clock::Lamport from above is this ID. Nathan continues:
[...] Basically, it's a way of getting a unique ID, right? The uniqueness is inherited from the replica ID, and then each replica is, of course, free to generate new Lamport timestamps all day long by incrementing their sequence number. It's really an ID for an insertion, for the original chunk of inserted text.
So, the timestamp is a unique ID assigned to an immutable block of text. The offset then describes the Anchors position in this piece of text that won't change, because, again, it's immutable. Nathan on the immutability:
Once we insert it, it's immutable. If you delete parts of it, we might hide them, tombstone them, but they're still there. And so that's how we achieve the collaboration. The whole thing is monotonically increasing. It's only accreting data over time. And because of that, I'm able to refer to insertion ID, whatever, offset, whatever. Now there's a lot of indexing and fanciness to figure out exactly where that is right now. But it's at least something we can like refer to that's stable. And that's why we choose to anchor it.
The Anchor, in Nathan's words, is "an anchor into this monotonically growing structure."
But here's the ultra neat part: that's not just useful for collaboration! Anchors are also used for background processing of text. Think about it: you want to send a piece of text to, say, a language server running in the background. You create two anchors — start and end of the selection — and start a background process with these two anchors to send the text over to the language server. Meanwhile, the user can continue typing and changing the text, because the two anchors will forever be valid, since they are anchored to a position in an immutable piece of text.
There you go — Point, Offset, UTF-16 counterparts, DisplayPoint, Anchor — who would've thought that we go from lines and columns to Lamport clocks?